Fraunhofer-Institut für Digitale Medientechnologie IDMT
Fraunhofer-Institut für Digitale Medientechnologie IDMT
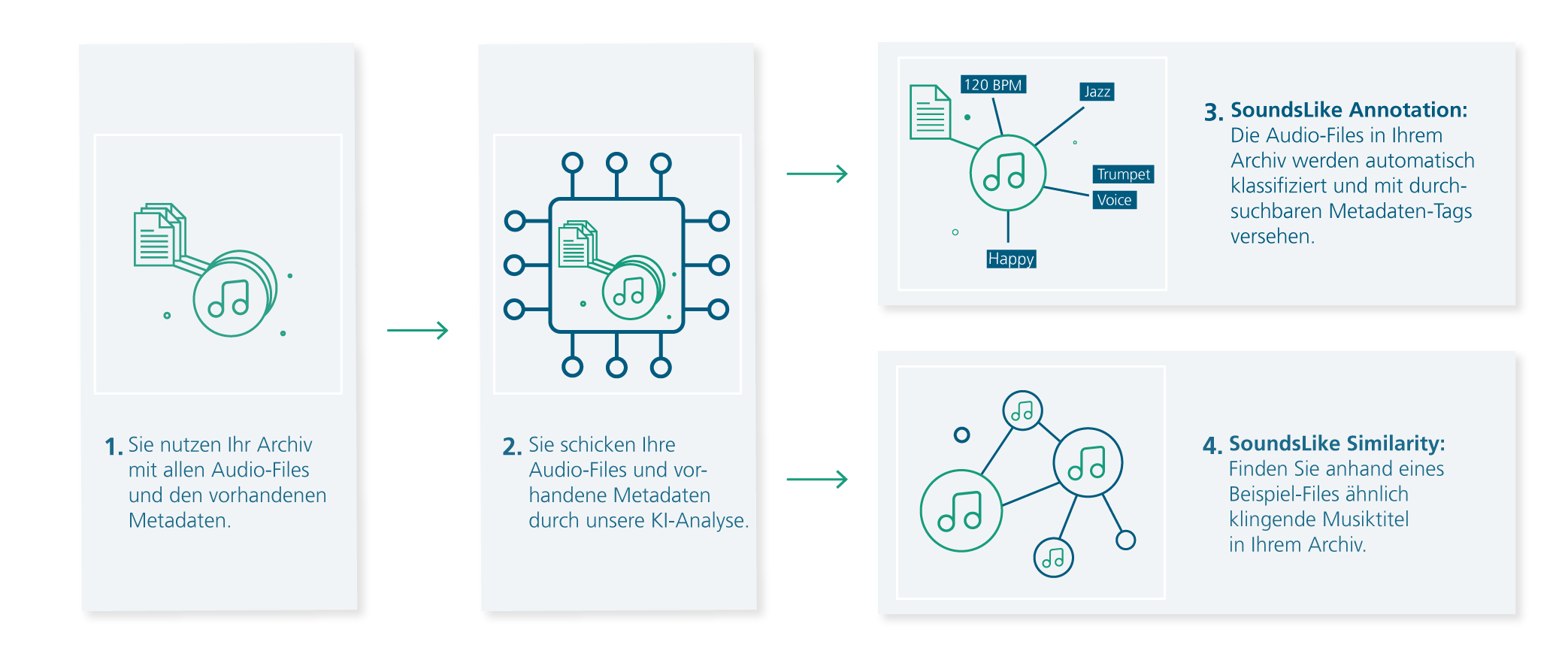
Verwandeln Sie Ihr Musikarchiv mit redaktionellen Metadaten automatisch in eine vollständig indexierte und durchsuchbare Datenbank. SoundsLike hilft Ihnen, alle Musiktitel in Ihrem Archiv nach dem gleichen Prinzip zu annotieren und ordnen – egal aus welcher Quelle sie stammen – doppelte Inhalte zu bereinigen und neue Tracks unkompliziert einzufügen.
Aus der KI-Forschung direkt in die Anwendung
Mit unserem fundierten Wissen im Bereich der Audiosignalverarbeitung und des maschinellen Lernens haben wir ein umfassendes Toolset an Musikanalyselösungen entwickelt. Von einzelnen Noten über Harmonieverläufe und Instrumentierungen bis hin zu Genres oder Stimmungen können wir eine große Vielfalt von Informationen aus Ihren Audiodaten extrahieren. Sie wählen genau die Kategorien und Daten, die zu Ihrem spezifischen Anwendungsfall passen.
Ihr Inhalt ist ihr Schatz - wir heben ihn gemeinsam.
Besitzen Sie bereits ein großes Archiv mit wertvollen Metadaten? Perfekt! SoundsLike nutzt künstliche Intelligenz, um ihr bestehendes Musikarchiv zu analysieren, zu verstehen, wie Ihr spezifisches Metadaten- und Kategoriensystem funktioniert und es so zu optimieren, wie Sie es brauchen. Ob vielfältige Produktionsmusik oder ein umfangreiches Klassikarchiv – SoundsLike hört zu, lernt und findet die passenden Kategorien und Unterkategorien für Ihren Musikkatalog.